
By Wilson Tang, Machine Learning Engineer in Threat Hunting
As a large, global organization with thousands of employees, Adobe creates and exchanges countless documents every day. These documents can range from less sensitive content drafts and proposals to highly sensitive documents, such as job offers or API documentation. With the potential risk of data exfiltration, it’s important to try and ensure that sensitive information found in these documents are not accessed by unauthorized users. Even a small number of files may cause an issue if they inadvertently fall into the wrong hands.
As the scale of cloud documents continues to grow, it’s become more difficult for organizations to correctly classify and detect a wide range of documents, including those that are sensitive. We cannot simply read all the documents manually in our environment with our human eyes. Moreover, properly flagging these documents has also become more difficult since the tooling hasn’t quite evolved to keep up with the scale and complexity of this issue.
At Adobe, we’re leveraging machine learning (ML) to help us detect various categories of sensitive documents, as well as implementing automated real-time detection and response to properly flag any detected documents. In this blog post, I will share how we’ve built these ML models and pipelines, as well as address some unique challenges that are more general to building ML models in the security domain.
What are sensitive documents?
To correctly model our problem, we must first clearly define our data as an ML task. We defined sensitive documents as files that contain any information that should not be shared broadly across the company. In addition to this general definition, we specified two (2) different classes of sensitive documents for the purposes of this project:
- Sensitive documents: Entire documents that are sensitive in nature. For example, job offers would be classified as sensitive documents because the job offer itself, in its entirety, is sensitive.
- Documents with sensitive information: Documents that aren’t sensitive in nature but contain some sensitive information. For example, API documentation isn’t inherently sensitive itself but could contain segments of sensitive information, such as an API key.
Leveraging Machine Learning (ML) for Document Classification
A specific category of artificial intelligence (AI), machine learning leverages a vast amount of data to build a model that can generate predictions on a given task. In this project, the task is to generate predictions for document classification.
Typically, document classification involves assigning a document one or more categories. There are many techniques for document classification; for our project, we found that random forests fit our needs best.
Simplifying Data with Vectors
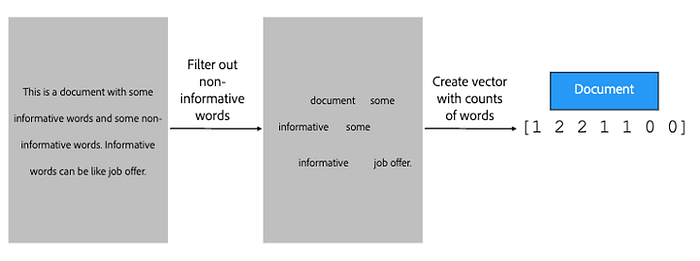
Before we could create a model, we needed to create a vector representation of a document. How did we do this? Let’s go over how we chose to represent our data. Given the raw text document, we first filtered out any non-informative words, meaning words that don’t help us determine whether the document is sensitive. By removing this noise in our data, we can more easily classify the sensitive documents.
Next, we create a vector with the word count in the document. Because we’ve filtered out the non-informative words, we should now have only a small set of words that makes it possible to use a vector representation. This technique is known as “bag of words”.
Improving Confidence with a Random Forest Classifier Model
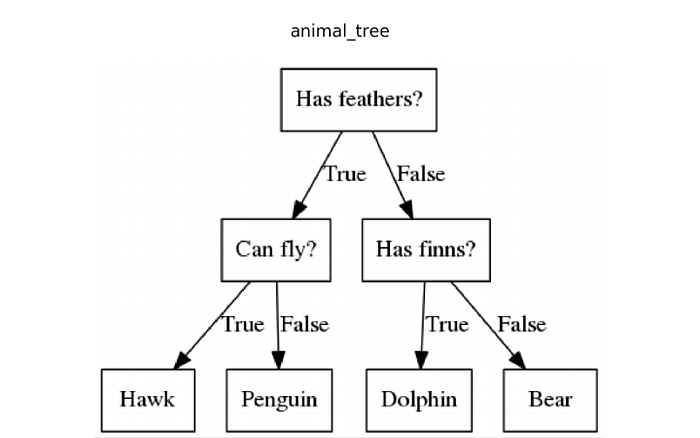
Now that we have our vector representation of the document, let’s dive into the model itself. A decision tree is a model that defines criteria and splits the input data into different branches. For example, in the model below, we are classifying animals. The different criteria for this tree are:
- Does the animal have feathers?
- Does the animal fly?
- Does the animal have fins?
Each decision we make on each criterion level puts the input in a different classification. We can imagine different criteria for identifying sensitive documents, such as “Does this document contain the phrase ‘job offer’?” Decision trees are very prone to overfitting. Overfitting happens when the decision tree creates decision boundaries that only work on the training data but don’t generalize to real-world data. This is a problem because the goal in ML is to create a model that predicts well on new data.
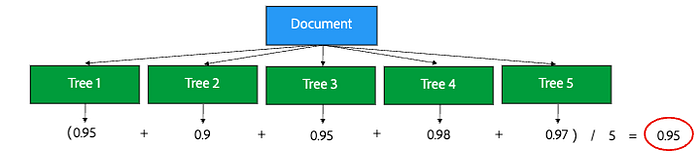
So, to reduce overfitting, we used a random forest classifier. This model trains multiple decision trees and averages the decision across all trees. The algorithm also ensures each tree trains on different criteria and splits by randomly selecting a different subset of features at each split. By using multiple trees, we train different models to make the same prediction in order to reduce overfitting.
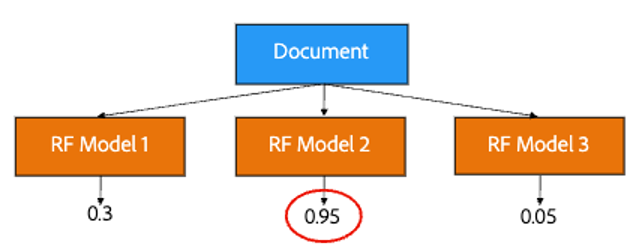
In addition to the random forest, we also implement one-vs-all classifiers. We train multiple random forest classifiers where each model specializes in classifying one specific document type. For example, one model can specialize in classifying job offers and another model can specialize in classifying tax documents. For each document, we run the text over each model and take the classification from the model with the highest confidence level.
Looking at the diagram below, let’s imagine the document is a job offer. You can see that random forest model two specializes in job offers with a predicted accuracy or confidence of 0.95, which is higher than the other two models.
Using Regex to Detect Patterns in Text
The random forest classifier technique fits well for wholly sensitive documents but doesn’t work for documents that only contain segments of sensitive information. For this class of sensitive documents, we implement regex detection, which searches for specific patterns in a text sample, thereby making it a well-suited for secrets and personally identifiable information (PII) use cases.
We use a combination of open-source and internally curated regexes for our implementation. An example regex for AWS API keys is shown below:

Automated Pipeline for Real-Time Detection and Response
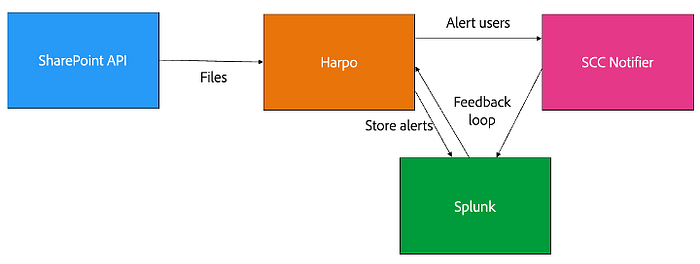
Finally, with our detection techniques, we’ve implemented an automated pipeline for real-time detection and response. We start with the SharePoint API, where we query all files for a specific time range. We then run each document over our models; if the document is classified as sensitive, we alert users directly through our User Notifier app and store the alerts in our security information and event management (SIEM).
In the alert, we enable users to indicate whether the document is sensitive with a “Yes” or “No” response, which is then sent back to our SIEM so we can constantly re-train our models.
Challenges
One challenge we faced during our ML project was establishing a reliable feedback loop. Especially in security, it is often difficult to label malicious or benign samples, as well as get user responses for training data. To address this issue, we leveraged using our User Notifier app to retrieve real-time user responses more easily, allowing us to continuously grow our data set.
Another challenge we faced was minimizing false positives. False positives are a key issue in security because we want to ensure our analysts won’t be flooded with alerts and experience “alert fatigue.” Random forests address this issue because even though they overfit less than decision trees, they still tend to overfit more often compared to other models. This means you’d get a much smaller false positive rate with random forests. Our current false positive rate on our test data is 0.8%.
However, as a side note, random forests generally tend to have a higher false negative rate, which means they could miss some sensitive documents. But because our use case where sensitive documents are typically uniform across the company, we found that random forests don’t tend to suffer from this false negative rate since different sensitive documents within the same category are very similar to each other. When the random forest picks up very specific features of the sensitive documents from the training data, it can accurately detect those features in new sensitive documents because of the uniformity. Therefore, both our false positive and false negative rates are very low.
Future Iterations
This project has enabled us to accurately classify a broad range of sensitive documents across the Adobe-wide SharePoint environment. In the future, we plan to grow this project by implementing more sophisticated ML models (such as BERT), continuing to expand our document categories, and extending our scanning capabilities to AWS S3 buckets and Azure storage blobs. We look forward to continuing our efforts in leveraging ML to help strengthen the security posture of our enterprise applications.
- Using Machine Learning to Help Detect Sensitive Information - April 11, 2023
- Safer Digital Experiences Start with Smarter Testing - February 21, 2023
- Standing Up a Security Program Management Office - February 2, 2023


